Parallelism and Computer Hardware
Our discussion so far has applied to an abstract computer with little reference to the physical machines. We are running multiple “processes,” vaguely defined, on some unspecified computer architecture. However, the hardware affects what types of parallelism we can apply and vice versa.
Hardware Taxonomy
Much of the classification for parallel computing is based on Flynn’s taxonomy. This was first developed in 1972 but much of it is still relevant. It is based on how many instruction streams (programming code) and data streams the hardware can handle
-
SISD Single instruction single data. Early computers had single processors that could run only one process at a time and could apply the instructions to only one data stream (thread) at a time.
-
SIMD Single instruction multiple data. The processor applies a code instruction to multiple threads of data at a time. Most modern graphical processing units (GPUs) are SIMD devices.
-
MISD Multiple instruction single data. Not widely encountered outside special-purpose computers such as those used for the Space Shuttle. In this category, multiple computers work on one set of data, such as sensor data.
-
MIMD Multiple instruction multiple data. Nearly all modern hardware falls into this category. This can apply either to multicore single computers or to distributed computing clusters.
High-Throughput Computing.
High-throughput computing (HTC) is also called “embarrassingly parallel” or “pleasingly parallel” computing In this form of parallelism, independent processes with little or no need to communicate are run simultaneously. This can involve data parallelism or task parallelism or both. High-throughput workloads can be run on any type of computer as long as multiple processes can be started on the system.
Examples of HTC include
-
Image processing, where the analysis of each frame is completely independent of all other frames.
-
Monte Carlo simulations. Hundreds or thousands of models are run with randomized parameters.
In principle, HTC is 100% efficient; in practice, some gathering and processing of results is necessary. For instance, in the image-processing example the end product may be a movie, in which case the frames will have to be encoded into a new file.
Shared-Memory Computing
Modern computers are essentially all multicore. All cores share the same
main memory. In most multicore systems, all cores have equal access to main
memory; hence these are called symmetric multiprocessing (SMP) systems.
They may not share the same cache, however. Some hardware utilizes a variant
called NUMA (non-uniform memory access), particularly servers with more than
one CPU socket. Graphical processing units (GPUs) are essentially shared-memory processors as well. Shared-memory parallel programs rely on internal
communication and coordination mechanisms, rather than external networks.

Distributed-Memory Computing
Large programs must generally be run on a cluster consisting of multiple compute nodes. Each node is an independent computer connected to the others through an external network. Because they are independent, one node has no direct access to the memory of any other node. Data must be transferred over the network from one node to another. This is accomplished by a library that manages the communication, invoked through an interface to the program.
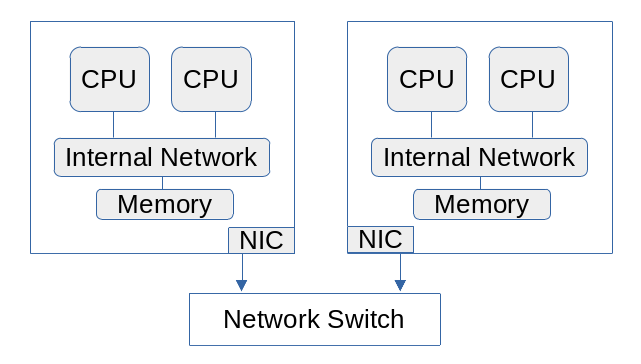
Hybrid Parallelism
Hybrid parallel programming is a combination of shared and distributed memory programming. Tasks and possibly some of the data are divided among the distributed executables that will run. Each executable also uses a threading library to split the work among the cores available on the node where it is running. Most commonly, this involves a combination of MPI for larger-scale data distribution and OpenMP at a smaller scale, often at the level of loops over data arrays.
GPU Parallelism
GPUs are essentially SMP processors with a large number, hundreds or even thousands, of lightweight “cores”; each core has a limited set of instructions it can carry out. The GPU has its own onboard RAM memory but relatively little cache. Efficient GPU programming keeps the cores busy with computations and reduces the number of times they must fetch data from or store data to their main memory. General-purpose GPUs are functionally “coprocessors” and data must be moved to and from the host to the GPU. This communication can be quite expensive and should also be minimized for efficient utilization of the system.