MPI Vector Type
Let us examine a specific application of the MPI Vector type. On each process, we will generate an identical matrix as the source, and another matrix of the same size, initialized to zeros, as the destination. A process will send the column (for C and Python) or row (Fortran) corresponding to its rank, to the next-higher indexed column or row in the next-higher rank; except for the last rank which will send its colunn/row to the first (zeroth) column/row of rank 0, i.e. the exchanges are cyclic.
C/C++
C, C++, Python, and many other languages are row-major oriented. That is, a two-dimensional array is mapped to linear memory by stacking one row after another, in order. In this illustration, we are going to place the zeroth column into a buffer.
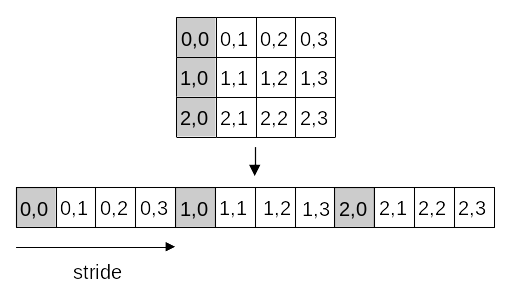
We start the selection at u[0][0]. The count, the number of items, is the number of rows, while the stride is the number of columns.
Since we are receiving into a column, we can use the same type to receive. The count, blocklength, and stride would be the same, but the starting location of the buffer might be different. The important invocations will look like this:
C++
//The length of the column is the number of rows
int ncount=nr;
//The number of items picked from each stride is 1
int blocklength=1;
//The length of the row is the number of columns
int stride=nc;
MPI_Datatype cols;
MPI_Type_vector(ncount,blocklength,stride,MPI_DOUBLE,&cols);
MPI_Type_commit(&cols);
MPI_Irecv(&w[0][0], 1, cols, src, tag, MPI_COMM_WORLD, &requests[0]);
MPI_Isend(&u[0][0], 1, cols, dest, tag, MPI_COMM_WORLD, &requests[1]);
The full code in C++
Contents of mpi_vector_type.cxx
#include <iostream>
#include <iomanip>
#include <mpi.h>
using namespace std;
int main (int argc, char *argv[]) {
int i, j;
int N;
// Added for MPI
int nr, nc;
int rank, nprocs;
int root=0, tag=0;
int src, dest;
//Initialize MPI
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD,&nprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
N = nprocs;
nr = N+2;
nc = N;
double **w=new double*[nr];
double *wptr=new double[(nr)*(nc)];
for (i=0;i<nr;++i,wptr+=nc) {
w[i] = wptr;
}
for ( i = 0; i < nr; i++ ) {
for (j = 0; j < nc; j++ ) {
w[i][j] = 0.;
}
}
double **u=new double*[nr];
double *uptr=new double[(nr)*(nc)];
for (i=0;i<nr;++i,uptr+=nc) {
u[i] = uptr;
}
double counter=1.;
for ( i = 0; i < nr; i++ ) {
for (j = 0; j < nc; j++ ) {
u[i][j] = counter;
counter++;
}
}
//#Cyclic sending
if (rank == nprocs-1) {
src=rank-1;
dest=0;
}
else if (rank==0) {
src=nprocs-1;
dest=1;
}
else {
src=rank-1;
dest=rank+1;
}
//These values pick a total of nc (ncount) items, one item
//(blocklength) taken for each nr (stride) items
//The length of the column is the number of rows
int ncount=nr;
//The number of items picked from each stride is 1
int blocklength=1;
//The length of the row is the number of columns
int stride=nc;
MPI_Datatype col;
MPI_Type_vector(ncount,blocklength,stride,MPI_DOUBLE,&col);
MPI_Type_commit(&col);
int nrequests=2;
MPI_Request requests[nrequests];
if (rank==0) {
MPI_Irecv(&w[0][0], 1, col, src, tag, MPI_COMM_WORLD, &requests[0]);
MPI_Isend(&u[0][0], 1, col, dest, tag, MPI_COMM_WORLD, &requests[1]);
}
else if (rank==nprocs-1) {
MPI_Irecv(&w[0][nprocs-1], 1, col, src, tag, MPI_COMM_WORLD, &requests[0]);
MPI_Isend(&u[0][nprocs-1], 1, col, dest, tag, MPI_COMM_WORLD, &requests[1]);
}
else {
MPI_Irecv(&w[0][rank], 1, col, src, tag, MPI_COMM_WORLD, &requests[0]);
MPI_Isend(&u[0][rank], 1, col, dest, tag, MPI_COMM_WORLD, &requests[1]);
}
MPI_Status status_arr[nrequests];
MPI_Waitall(nrequests,requests,status_arr);
//Try to print neatly
//U is the same for each rank in this example
if (rank==0) {
cout<<"U"<<endl;
for (i=0;i<nr;i++) {
for (j=0;j<nc;j++) {
cout<<setprecision(6)<<u[i][j]<<" ";
}
cout<<endl;
}
}
MPI_Barrier(MPI_COMM_WORLD);
cout<<endl;
MPI_Barrier(MPI_COMM_WORLD);
cout<<"W for rank "<<rank<<endl;
for (i=0;i<nr;i++) {
for (j=0;j<nc;j++) {
cout<<setprecision(6)<<w[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
//Type_free not really necessary but good practice
MPI_Type_free(&col);
MPI_Finalize();
}
Python
As we have discussed, when sending MPI types we must extract the raw data from a NumPy array.
#The length of the column is the number of rows
ncount=nr
#The number of items picked from each stride is 1
blocklength=1
#The length of the row is the number of columns
stride=nc
cols = MPI.DOUBLE.Create_vector(ncount, blocklength, stride)
cols.Commit()
recv_request=comm.Irecv([np.frombuffer(w.data,np.double,offset=sendcol*np.dtype('double').itemsize),1,cols],src)
send_request=comm.Isend([np.frombuffer(u.data,np.double,offset=recvcol*np.dtype('double').itemsize),1,cols],dest
The full code in Python
Contents of mpi_vector_type.py
import sys
import numpy as np
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
nprocs = comm.Get_size()
N = nprocs
nr = N+2
nc = N
u = np.arange(1,nr*nc+1).reshape(nr,nc)
w = np.zeros_like(u)
#Cyclic sending
if rank == nprocs-1:
src=rank-1
dest=0
elif (rank==0):
src=nprocs-1
dest=1
else:
src=rank-1
dest=rank+1
#These values pick a total of nc (ncount) items, one item
#(blocklength) taken for each nr (stride) items
#The length of the column is the number of rows
ncount=nr
#The number of items picked from each stride is 1
blocklength=1
#The length of the row is the number of columns
stride=nc
cols = MPI.DOUBLE.Create_vector(ncount, blocklength, stride)
cols.Commit()
if rank==0:
recv_request=comm.Irecv([np.frombuffer(w.data,np.double,offset=0),1,cols],src)
send_request=comm.Isend([np.frombuffer(u.data,np.double,offset=0),1,cols],dest)
elif rank==nprocs-1:
sendcol=nprocs-1
recv_request=comm.Irecv([np.frombuffer(w.data,np.double,offset=sendcol*np.dtype('double').itemsize),1,cols],src)
send_request=comm.Isend([np.frombuffer(u.data,np.double,offset=sendcol*np.dtype('double').itemsize),1,cols],dest)
else:
sendcol=rank
recv_request=comm.Irecv([np.frombuffer(w.data,np.double,offset=sendcol*np.dtype('double').itemsize),1,cols],src)
send_request=comm.Isend([np.frombuffer(u.data,np.double,offset=sendcol*np.dtype('double').itemsize),1,cols],dest)
requests=[recv_request,send_request]
MPI.Request.Waitall(requests)
cols.Free()
#Print neatly
#U is the same for each rank in this example
if rank==0:
print("U")
for i in range(nr):
for j in range(nc):
print("{:12.6f}".format(u[i,j]),end="")
print()
print()
comm.Barrier()
print("W for rank", rank)
comm.Barrier()
for i in range(nr):
for j in range(nc):
print("{:12.6f}".format(w[i,j]),end="")
print()
print()
Fortran
Fortran is colum-major oriented. Memory is laid out by columns. In this illustration, we are selecting the fourth row to place into the buffer.

The buffer will start at u(3,1). As for C++ and Python, we can use the same vector type for sending and receiving.
Our code snippet would look something like this.
! The length of the row is the number of columns
ncount=nc
! The number of items picked from each stride is 1
blocklength=1
! The length of the column is the number of rows
stride=nr
call MPI_Type_vector(ncount,blocklength,stride,MPI_DOUBLE_PRECISION,rows)
call MPI_TYPE_COMMIT(rows)
call MPI_Irecv(w(1,1),1,rows,src,tag,MPI_COMM_WORLD,mpi_requests(1))
call MPI_Isend(u(3,1),1,rows,dest,tag,MPI_COMM_WORLD,mpi_requests(2))
The full code in Fortran
Contents of mpi_vector_type.f90
program sendrows
use mpi_f08
implicit none
double precision, allocatable, dimension(:,:) :: u,w
integer :: N
integer :: i,j
integer :: nr, nc
integer :: rank, nprocs, tag=0
integer :: ncount, blocklength, stride
integer :: nrequests
type(MPI_Status), dimension(:), allocatable :: mpi_status_arr
type(MPI_Request), dimension(:), allocatable :: mpi_requests
type(MPI_Datatype) :: row
integer :: src, dest
!Initialize MPI, get the local number of columns
call MPI_INIT()
call MPI_COMM_SIZE(MPI_COMM_WORLD,nprocs)
call MPI_COMM_RANK(MPI_COMM_WORLD,rank)
N=nprocs
nr=N
nc=N+2
nrequests=2
allocate(u(nr,nc),w(nr,nc))
allocate(mpi_requests(nrequests),mpi_status_arr(nrequests))
u=reshape([(i,i=1,nr*nc)],(/nr,nc/))
w=0.0d0
!Cyclic sending
if (rank == nprocs-1) then
src=rank-1
dest=0
else if (rank==0) then
src=nprocs-1
dest=1
else
src=rank-1
dest=rank+1
endif
! These values pick a total of nc (ncount) items, one item
! (blocklength) taken for each nr (stride) items
! The length of the row is the number of columns
ncount=nc
! The number of items picked from each stride is 1
blocklength=1
! The length of the column is the number of rows
stride=nr
call MPI_Type_vector(ncount,blocklength,stride,MPI_DOUBLE_PRECISION,row)
call MPI_TYPE_COMMIT(row)
if (rank==0) then
call MPI_Irecv(w(1,1),1,row,src,tag,MPI_COMM_WORLD,mpi_requests(1))
call MPI_Isend(u(1,1),1,row,dest,tag,MPI_COMM_WORLD,mpi_requests(2))
else if (rank==nprocs-1) then
call MPI_Irecv(w(nprocs,1),1,row,src,tag,MPI_COMM_WORLD,mpi_requests(1))
call MPI_Isend(u(nprocs,1),1,row,dest,tag,MPI_COMM_WORLD,mpi_requests(2))
else
call MPI_Irecv(w(rank+1,1),1,row,src,tag,MPI_COMM_WORLD,mpi_requests(1))
call MPI_Isend(u(rank+1,1),1,row,dest,tag,MPI_COMM_WORLD,mpi_requests(2))
endif
call MPI_Waitall(size(mpi_requests),mpi_requests,mpi_status_arr)
call MPI_TYPE_FREE(row)
!Print neatly
! U is the same for each rank in this example
if (rank==0) then
write(*,*) "U"
do j=1,nr
write(*,'(*(g12.6))') u(j,:)
enddo
endif
call MPI_Barrier(MPI_COMM_WORLD)
do i=1,nprocs
call MPI_Barrier(MPI_COMM_WORLD)
if (rank==i-1) then
write(*,*)
write(*,*) "W for rank ",rank
do j=1,nr
write(*,'(*(g12.6))') w(j,:)
enddo
endif
enddo
call MPI_Type_free(row)
call MPI_Finalize()
end program