Machine Learning and Deep Learning
Machine Learning Overview
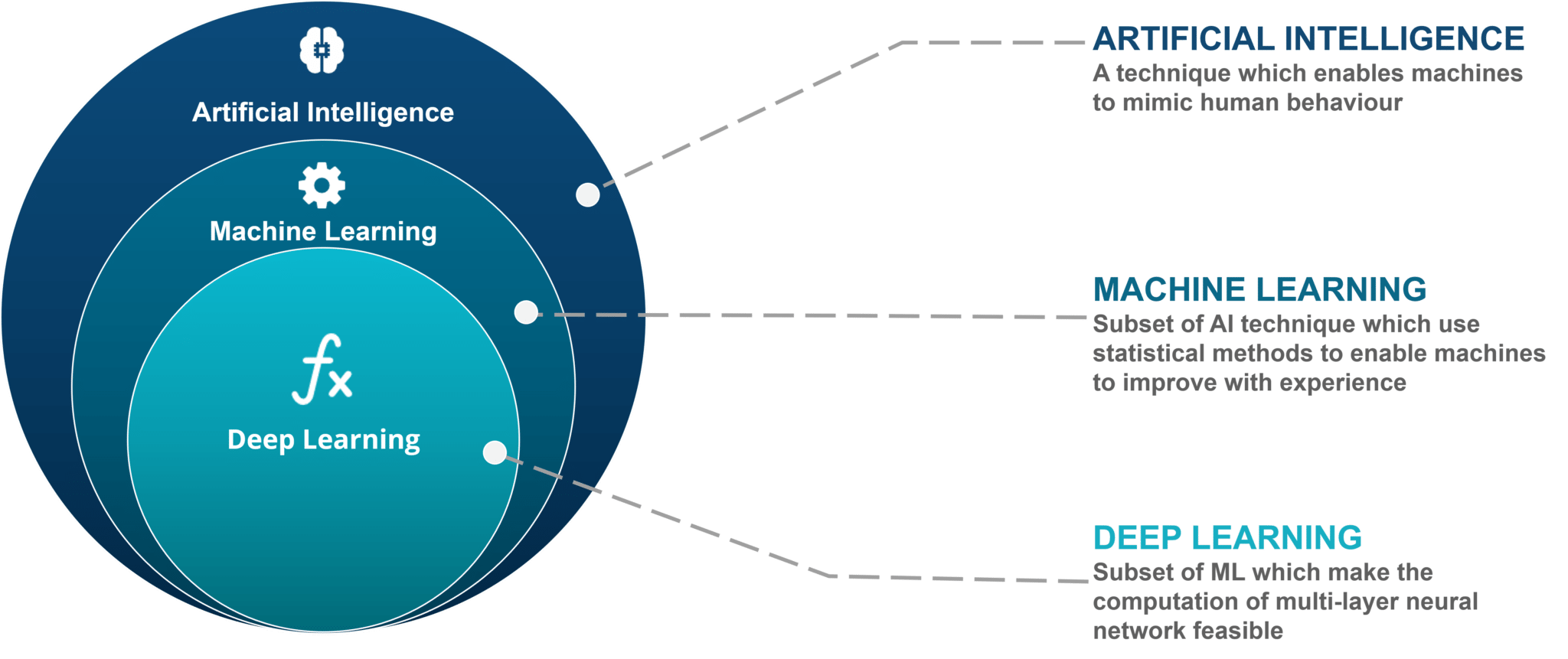
Machine learning (ML) is a branch of artificial intelligence where computers learn from data and adapt the computational models to enhance performance. It is a method of analysis that allows computers to reveal information within data.
- The “learning” is not the type of learning that you and I do.
- It is a systematic approach to finding an appropriate data transformation from inputs to output.
Why ML?
- Computers can sort through data faster than humans can.
- Computers can identify patterns quickly and use these patterns for predictions or classifications.
- Machine learning can handle noisy data – it doesn’t find a perfect answer, but rather a “really good” answer.
Applications of ML
- Regression techniques
- Determines a mathematical model for the relationship among features or attributes so that an outcome can be predicted.
- Results can be any value within a possible range (e.g., what will the average Earth temperature be in 2050?)
- Classification problem
- Identifies a combination of attributes that best fits a class or category so that an object can be classified.
- Results can be from a list of known possibilities (e.g., is the tumor benign or malignant?)
Note: Examples included in this tutorial are all of classification type problems.
Types of ML
- Supervised Learning:
- A data set exists where the samples can be categorized into two or more classifications.
- The computer uses the data set to learn how to predict the classification of an unknown sample.
- Examples include Decision Trees and Deep Learning
- Unsupervised Learning:
- The collected data has no known classification or pattern.
- The computer must identify the groups or hidden structures within the data.
- Examples include Dendograms, K-means clustering, Self-organizing Maps
- Reinforcement Learning:
- Computer learns from positive or negative feedback
- Example includes Swarm intelligence
Note: Examples included in this tutorial are all instances of supervised learning.
Data for ML
- For many Machine Learning algorithms, the data is expected to be in a table format, where:
- each row represents an object, and
- each column has the measurements for a specific attribute or feature of the object
- For supervised learning, the classifications of the objects must be known.
- The data with known classifications are divided into a training set and a testing set.
- The data is then used to develop a model.
- The training data are submitted to an algorithm that will fit a model to the data.
- The test data are submitted to the model to produce predicted classifications and determine the accuracy of the model.
- Finally, the model can be used to predict classifications for “unknown” data.
ML Algorithm
The algorithm determines the best mathematical model for the code. However, you still need to provide a “framework” for the algorithm. The framework provides the algorithm with tools for performing the learning.

Deep Learning vs Machine Learning
- Deep Learning is a subset of Machine Learning that differentiates itself from ML algorithms based on the methods (neural networks) it uses to solve problems.
- Any deep learning algorithm would reiterate and perform a task repeatedly, improving a bit every time, in order to improve the outcome.
- A deep learning program builds the feature set by itself without supervision and domain expertise.
- Unsupervised learning is not only faster, but it is usually more accurate.
- Unsupervised learning needs access to immense amounts of data and compute power and takes much longer to train, but it is much faster to run tests.
- Unsupervised learning is not only faster, but it is usually more accurate.
- ML algorithms have superior interpretability and are favorable for small amounts of data.
- ML works only with sets of structured and semi-structured data, while deep learning works with both structured and unstructured data
Limitations and Challenges
- DL models learn through observations. Outcome is not ”generalizable” if data was small or if its scope was limited.
- If a model trains on data that contains biases, the model will reproduce those biases in its predictions.
- If the learning rate is too high, then the model will converge too quickly, producing a less-than-optimal solution. If the rate is too low, then the process may get stuck, and it will be even harder to reach a solution.
- There are a large amount of data and parameters.